Let’s start from the basics. Data products are one of the key concepts of Data Mesh, which emphasizes that data can be a product internal to or external to the organization. Data Mesh is a paradigm of building data platforms in a decentralized way to support and serve the structure and design of organizations.
In simple words, ‘data as product’ in the Data Mesh context are pieces of data that are packaged, owned, and maintained in a manner similar to the way software products are treated. Examples of data products can include a dashboard for the CMO or CFO, a dataset with customer data, or an ML model used by the Customer Success Team, or a single data table with calculated metrics for the Sales Team. In other words, it depends on company structure – data domains and JTBD (Job to Be Done) with data products. A crucial question is how to design this architecture and data structure to be reusable, easily accessible, and trustworthy for all teams interested in specific data products.
Data products: cycle and attributes
Data products have its life cycle as any product in software, marketing, or any other domain.
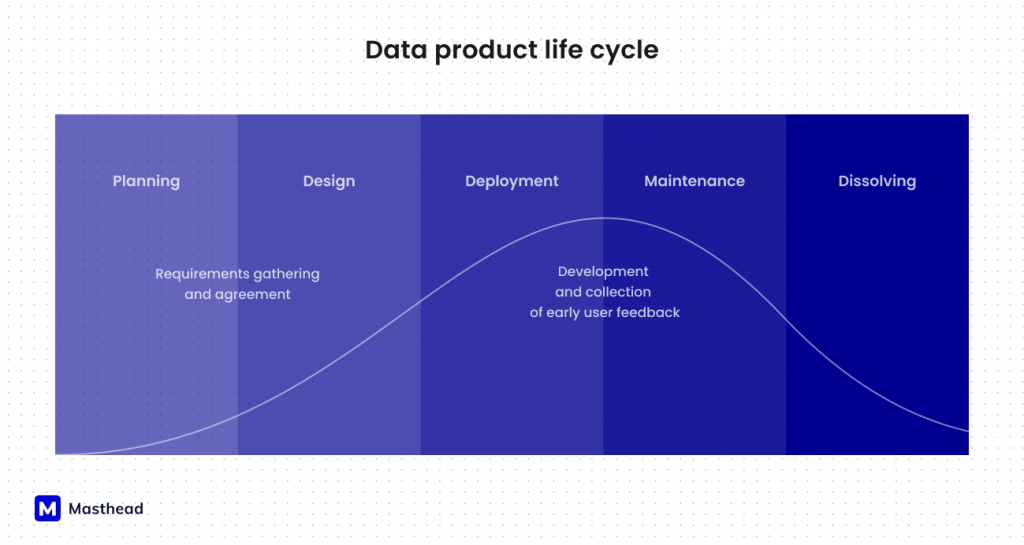
In addition to their lifecycle, Data Products also need to possess certain attributes to succeed: having a clearly defined owner, clearly defined consumer(s), belonging to a specific domain, and having a defined data product quantum, which can vary from data product to data product.
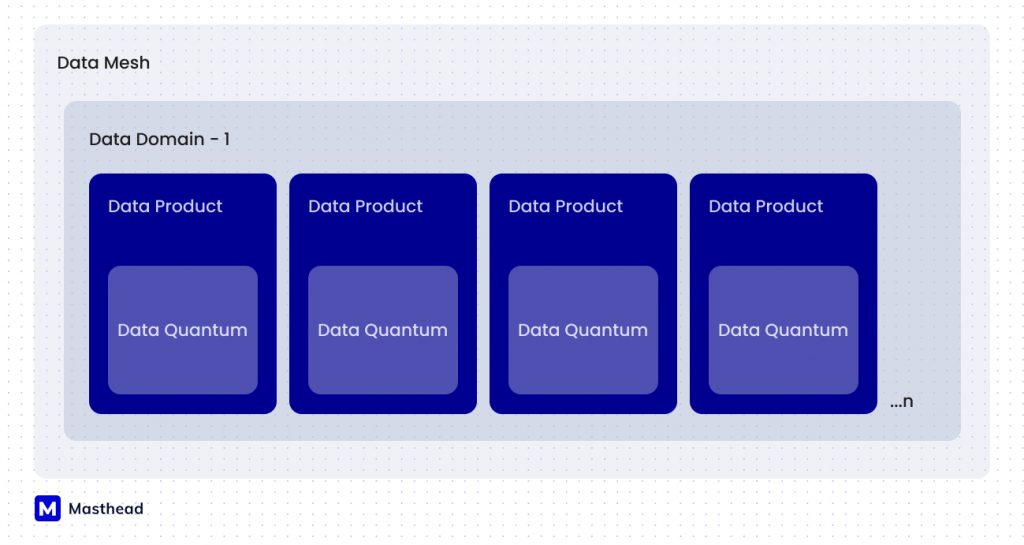
Data products are outputs of IT and Data infrastructure that are designed to create business outcomes, while Data Mesh guides and supports data architecture that meets business requirements and enables businesses to extract value from data faster.
Data products characteristics
Via Data Mesh, data is viewed as a product. The ultimate goal is to put data into action and generate measurable value for businesses. With that said, generating business outcomes is a core characteristic that defines the existence of data products. This value varies depending on the business, domain, use case, and many other factors. How the value of data products is measured and determined depends on the specific team that possesses the relevant business context. For example, the sales team owns a particular data table and is responsible for ensuring it is updated on time, maintaining the reliability of the data, and managing the data product effectively to deliver the best business outcomes possible.
Another characteristic of data products is that they are discoverable. While this might seem straightforward, considering the ever-growing volume of data, pipelines, and models, ensuring data products are easily accessible is crucial. Data consumers need the ability to access these products effectively for practical use.
On top of that, all data products in the organization should be standardized, ensuring that, even though they are decentralized and owned by different teams, there are consistent standards for how data is accessed, secured, and used to ensure consistency and reliability.
A very good and simple analogy for data mesh and data products is the way books are organized in a library. Books, akin to data products, are typically stored in different sections or domains of the library, such as fiction, novels, education, etc. Each book is stored in a specific domain and is usually easy to search for, being grouped by year or author’s name. Moreover, there are usually designated individuals responsible for maintaining order in these domains (book aisles).
This concept may seem theoretical, but it becomes practical when data practitioners and businesses begin to implement data mesh and define data products.
How do we identify “Data products”?
I am graciously moving forward, assuming we have C-level buy-in for the Data Mesh project with all necessary approved budgets, allocated capacity and resources, and enormous faith to adopt Data Mesh company-wise
It’s interesting to note that Data Mesh aims to minimize data in storage by focusing on eliminating unnecessary elements and retaining only what is essential for business. This approach stands in contrast to the common business practice over the past 15 years of accumulating all possible events and data points, adhering to the principle, ‘We might need it tomorrow, who knows?’ Yet, I have not come across an organization where someone would be willing to delete data to free up some storage deliberately.
As data products are an actual output of Data Mesh, the question arises: how do we then define them? The approach that has gained the most traction and benefited companies is where data teams start talking to their data consumers, trying to define the Jobs To Be Done (JTBD) with the data before they are identified as data products. Exceptional data engineers have taken proactive steps, getting out there and asking business people simple questions:
- What problem are data consumers trying to solve?
- What are they currently doing to solve it?
- What will happen if they no longer have the data they currently use?
- What data is missing?
- What is the estimated value added by having this data at their disposal?
These simple questions help both parties involved to justify transforming what they have into a data product with all necessary characteristics. Yet, this very conversation puts the data engineer in a completely new perspective, where they take on the role of a product manager.
Why does adopting a product manager mindset matter so much for success in Data Mesh?
Early investigation and scoping of the problem solved using data are crucial. It helps define the architecture of the future data platform, determine resource allocation for building and maintaining it, and identify the necessary tools to support the infrastructure. Having an open conversation and environment to collaborate for data teams and business users is essential for future decisions on updating, iterating, or decommissioning data products and, eventually, data platform.
Many organizations opt to hire a data product manager for this role. This role takes ownership of data products, scopes them out, and prioritizes tasks essential for business success. However, this role is not strictly necessary if a member of the data team is proactive enough to take on additional responsibilities. Nevertheless, it should not be taken for granted, as this data product management role implies a lot of work on planning, synchronizing, prioritizing, and keeping every stakeholder in the loop, to ensure that data products are delivered and provide the expected value to the business.
The necessity of having a data product manager onboard largely depends on the maturity of both the data team and the organization as well as the life cycle of the data products in the organization.
Final thoughts
Focusing on JTBD is distinguishing from what data consumers want and need, which eventually generates business value. This, also done in hand, with strict prioritization. Understanding all potential users within other domains and how it should be standardized. While developing any data projects, data teams need to be focused on the Job to be done and then on technology. To achieve this, the data team might need a dedicated role of data product manager who will keep a bigger picture and run all the necessary work of gathering requirements, prioritizing things, and keeping all stakeholders updated and engaged. With that said, we should not expect that from data engineers, though focusing on value and results for users should be a top priority for data engineers, where data product managers can guide them to develop the necessary mindset on building data products that are used rather then data sets that sits somewhere in storage.




