Data mesh architecture is revolutionizing the way organizations handle data. This guide offers a comprehensive look at its benefits, challenges, and how it compares to traditional data architecture approaches.
Key Challenges Addressed by Data Mesh Architecture
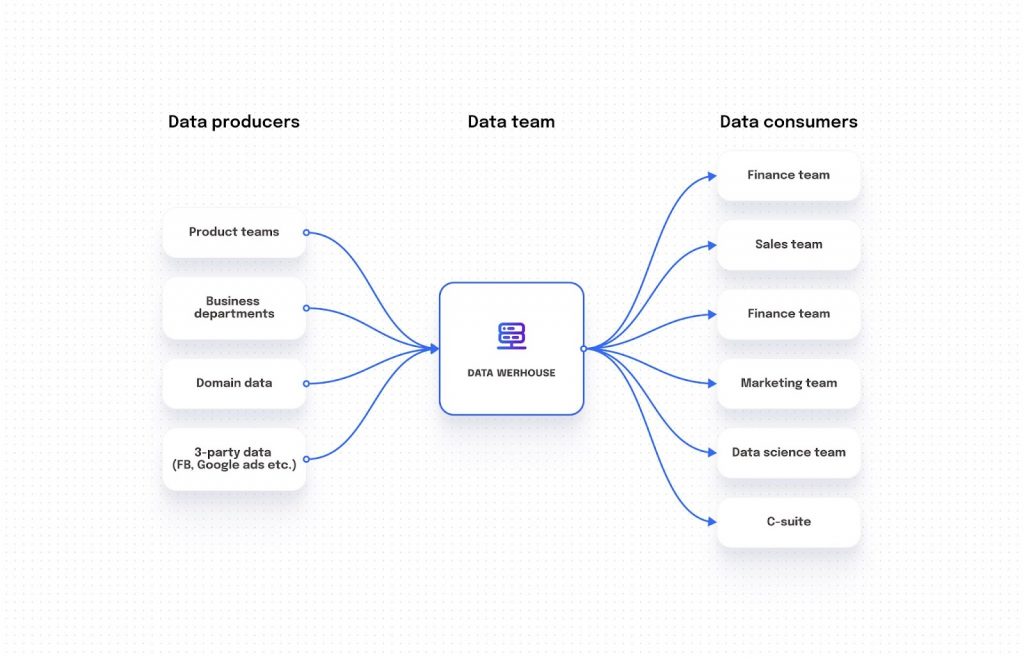
Data mesh terms have been increasingly appearing in data blogs and podcasts. This brings up the question: Is it just another buzzword, or does it represent the legitimate future of data architecture? Before diving in, it’s crucial to comprehend what current data architecture within organizations entails.
On the left-hand side, we have data producers. These range from production teams responsible for specific microservices, to departments churning out domain data, and even third-party data sources like Facebook ads and Google ads.
Conversely, on the right, are data consumers. These predominantly include operation teams: marketing, sales, customer success, data science teams, and organizational leadership.
Centralized data architecture introduces several core issues:
- Monolithic Structure: Data lakes and warehouses adopt a centralized structure. Over time, this can lead to bloated and complex data storage, triggering issues like duplication and mismanagement.
- Data Pipeline Failures: Constant breakages in data pipelines present a significant hurdle for data engineers. The underlying issues often lie in undefined data or inconsistencies within data movement.
- Expertise Challenges: For data engineers and analysts, mastering the collected data is no small feat. It requires understanding the nature of data sources and even the applications producing the data.
Data Mesh vs. Microservice Architecture: Decoding the Connection
Enter the concept of data mesh. Contrary to some beliefs, data mesh isn’t a tool but a modern data architecture philosophy. It accentuates decentralized data management and governance. Zhamak Dehghani coined the term “Data Mesh” in 2019, presenting it as a decentralized method for storing and managing organizational data. The central tenet of data mesh is to equip organizations with a scalable, maintainable, and decentralized data environment.
A popular analogy is comparing data mesh to microservice architecture in software development. However, while there are parallels, it’s essential to note that the rise of data mesh is an unintended consequence of today’s microservice-centric landscape.
When is the Right Time to Adopt Data Mesh in Your Organization?
The data mesh concept is still being built, with not many established best practices. Yet, some firms have started leveraging it to construct scalable and reliable data architectures. A fundamental principle here is “Domain Data Products,” emphasizing that data producers should own and treat their data as a product. Investing in The Data Product Strategy and identifying all stakeholders should be an initial step toward building a robust data mesh.
For instance, consider an HR department with various applications. Under the data mesh framework, all data from these apps should be managed and governed by the HR team itself. The goal is to promote data ownership across the organization, with each department treating data as its product.
However, embracing data mesh is not without challenges. It demands extensive resources, high data literacy, and a commitment from every organizational member. Given the complexity and nuances involved, it’s challenging to visualize a large-scale company seamlessly transitioning to this system.
While implementing data mesh in its entirety may seem daunting, organizations can still incorporate some of its incremental ideas. Such steps, albeit small, can foster better data ownership and enhance data quality and reliability.
In summary, Data Mesh Architecture offers a decentralized approach to data management, addressing many challenges faced by organizations today. While its complete implementation may be intricate, embracing its core principles can lead to better data governance and efficiency.
If you are currently implementing Data Mesh at Google Cloud, see the webinar: Data Mesh on Google Cloud Stack- Insights, Starting Points and Evading Pitfalls with Yuliia Tkachova, CEO @ Masthead Data, and Simon Messey, Director @ Data Mesh Solutions and ex-Data Mesh Lead at HSBC.




