It is great that the data industry has moved beyond the notion that data quality equals data observability and data reliability. If you still find the distinction unclear, I highly suggest looking into Sunjeev’s article and the diagram explaining its core components.
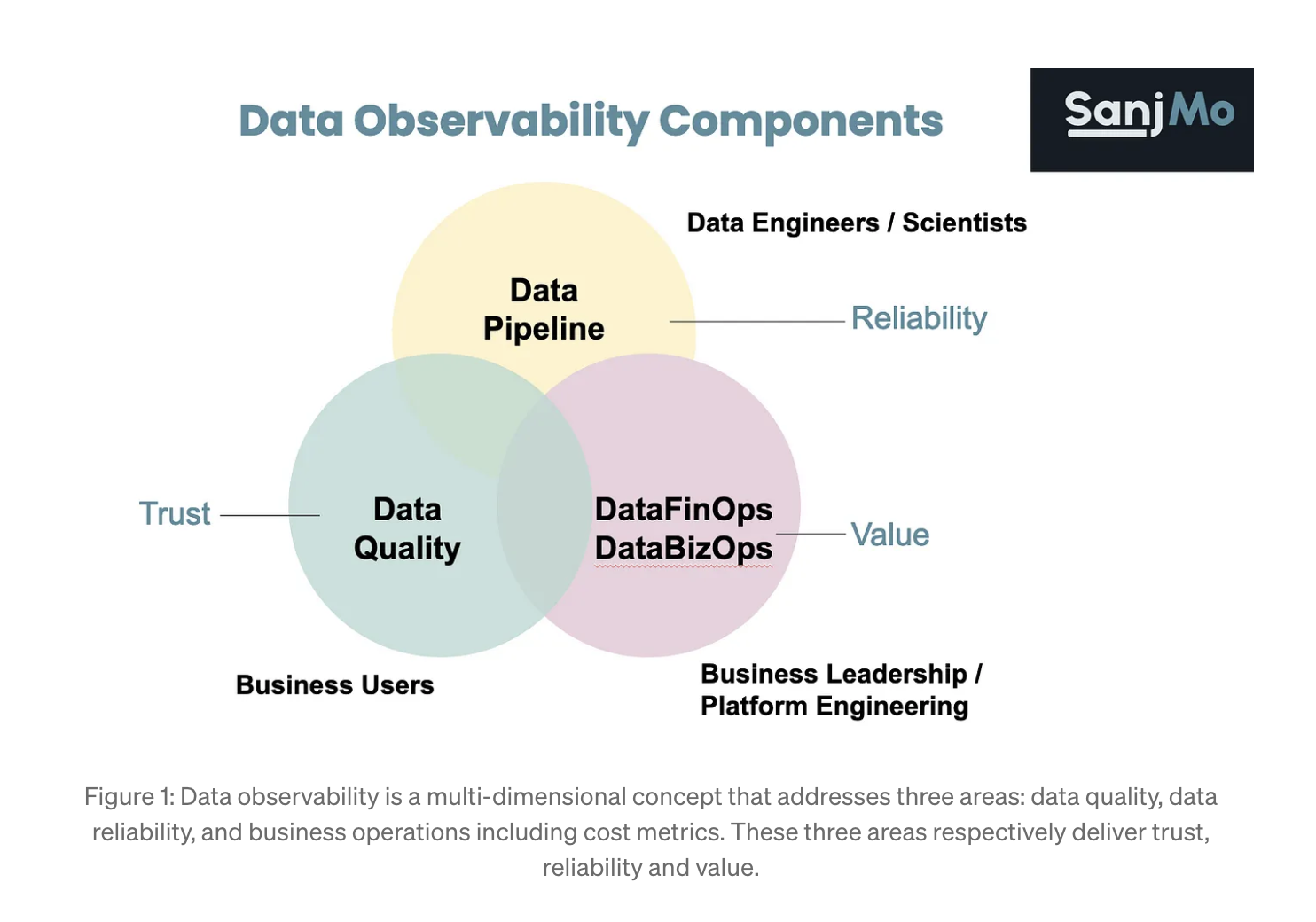
Sanjeev did a great job explaining why FinOps should be viewed as a part of data observability. To summarize briefly, data FinOps should be included in data observability practices because data teams need to understand resource usage, communicate it to business stakeholders, and ensure resources are deployed efficiently to justify the data platform’s ROI. I highly recommend reviewing the article if you haven’t already done so.
Another trend is that more SQL-first data observability solutions are starting to integrate with data modeling and data ingestion solutions to provide coverage beyond tables, which is great. However, there are a few questions you should consider when evaluating how any solution delivers pipeline observability. These questions will help align expectations and evaluate the pipeline observability solution or practice:
- What is the percentage of pipeline coverage to expect?
- How intrusive is the integration?
- How much time and effort does it take to implement?
- What issues is pipeline observability designed to help data teams with?
- How is the solution powered? What data is leaving your environment?
Heads up, this piece might be biased as I’m one of the co-founders of Masthead. Our solution offers automated pipeline observability, covering all data pipelines regardless of solutions powering pipelines in the client’s data platform. Still, the questions above are influenced by extensive interactions with data professionals and our clients in pursuit of understanding what truly matters for data teams.
What is the percentage of coverage one should expect?
I think this is the most important question for evaluation. I do not believe in observability for a fraction of tables or processes. In other words, it’s either you cover everything, or it turns out to be just monitoring, which is also fine but not observability. Most vendors propose integrating with popular data stacks like Fivetran or dbt Cloud/Core, but this does not guarantee full coverage. Often, there could be Python scripts, Hivo, Airbyte, Stitch, and more under the hood. Traditional SQL or direct connectors from Looker to your data warehouse can also be overlooked. The question is, how do you know what processes are in your data platform and what solutions are powering them? It is often a challenge for teams to keep track, but this is essential to understand the coverage provided by a particular vendor.
How intrusive is the integration?
Well, this is what I keep emphasizing to every data person. If the solution does not ingest or model your data, it should not have edit rights in your data warehouse. I suggest carefully reviewing which solutions have read permissions. It might be a security task, but it’s good to know.
How much time and effort does it take to implement?
This is crucial. If the implementation is too tedious, such as requiring SDKs or code in each pipeline to achieve full observability, consider how much time and how many people it will take. This will also require ongoing maintenance. I met a team of 10 engineers who have been working on implementing an open-source solution for over two months due to its complexity and lack of internal knowledge. I’m unsure if they will see the end of this journey soon. This might not be the case for every team, but it’s essential to consider the data team’s shift in focus. Investing in open-source data observability might be a good choice if there is no pressing business use case, which seems unlikely today.
What issues is pipeline observability designed to help data teams with?
Another good question is, what metrics about the pipeline in your data platform would you want to collect to improve the data platform? One of the features our clients love at Masthead is helping data teams surface any errors that occur during pipeline execution in the client’s data environment. Examples of errors could be anything from syntax errors, mismatched signatures for operators, invalid columns—literally anything.
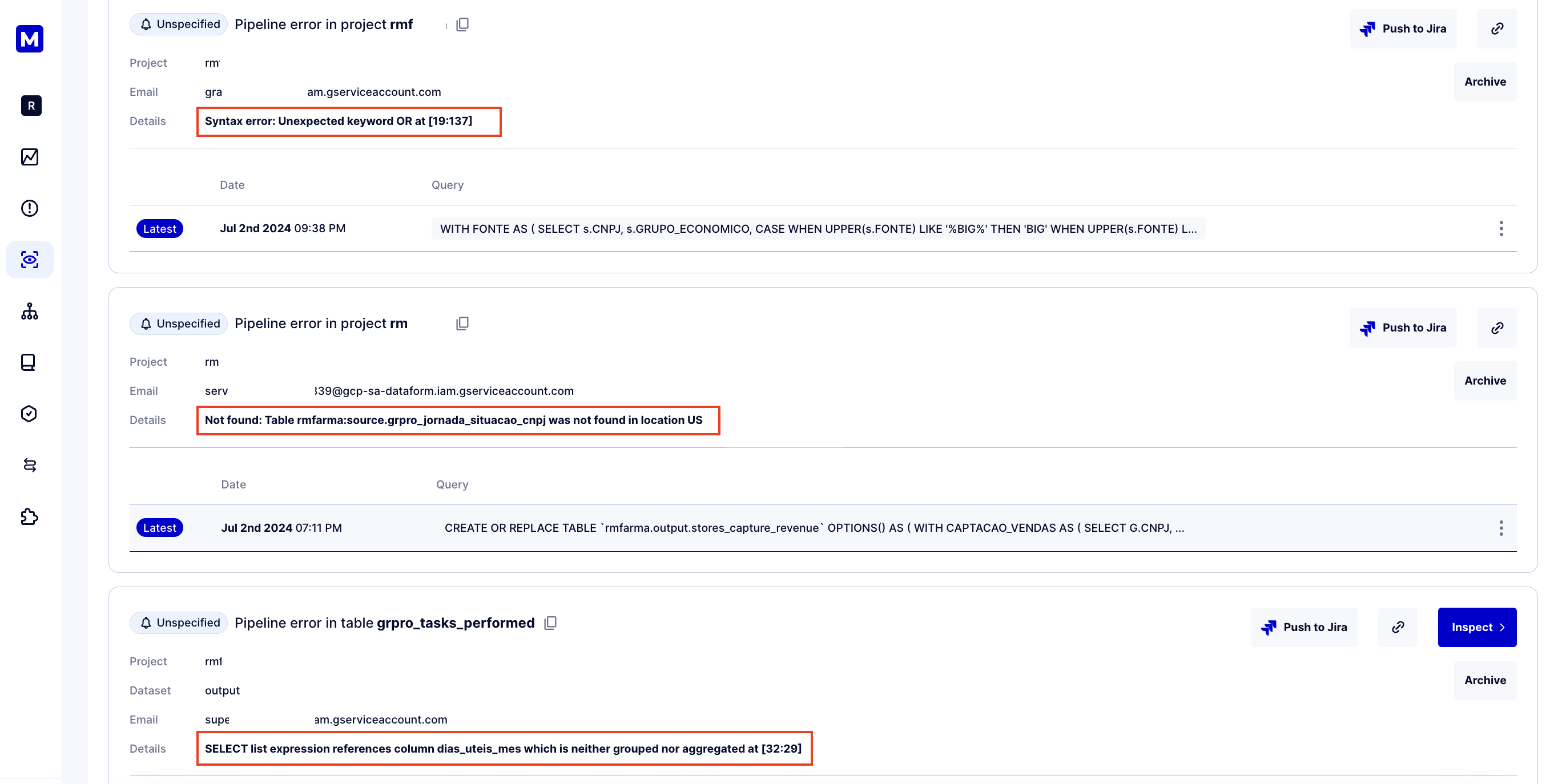
However, another set of pipeline issues involves pipeline execution. These could include anomalies in the time it takes for the pipeline to execute, resources consumed during each execution, or even a failure to run the pipeline, meaning it was not fired at the expected time.
You might ask, why should we care about a missing pipeline run if we can see missing data through freshness anomalies in the destination table? That is absolutely true if we are talking about one pipeline to the destination table. However, it is easy to lose track of things if there is more than one pipeline updating the table. If a pipeline that is supposed to update 10% of data suddenly fails to run, this kind of anomaly will likely be overlooked, even with data observability in place.
Anomalies in pipeline execution time or resource consumption received a great response from our clients, as it helped them identify unexpected resource usage. For many customers, this indicated that their pipelines should be simplified or at least reviewed. In other cases, it was a clear sign that, due to system overload and too many pipelines firing simultaneously, the team needed to come up with better scheduling to avoid running into reserved resource allocation.
How is the solution powered? What data is leaving your environment?
I’m sure everyone has already started taking data security and privacy seriously, but referring to Sunjeev’s article, not every data team understands the true cost of ownership of the tools used in their data stack.
I often have conversations with data engineering teams who say something like, “Oh, we use dbt tests to handle data observability and quality.” This is a great solution to a problem, but it is still SQL, and if not done using best practices, it can significantly increase compute costs. We had a case with one of our clients where dbt tests were responsible for about 30% of their total compute costs. The truth is that data teams do not necessarily know how much dbt costs them, and moreover, they do not realize how much-repeated test costs contribute to their cloud bill.
The Farewell Thoughts
It is up to the data engineering team to decide if they need pipeline observability for their data platform. I cannot agree more with Sanjeev’s pillars of data reliability and user personas for each being different. Pipeline observability serves data teams, often data engineers, while data quality often answers the questions of business users.
Another point to consider is that business users, who often happen to be budget holders, do not necessarily understand why a data platform, including pipelines, needs to be observed. They simply do not see how it impacts the data products they use daily, as they may already have simple checks in place. I think it is essential for the data team to build this bridge and explain why pipeline observability at scale matters as much as anomaly detection in data.
_ _ _
Almost forgot, next time you think something like: “Oh, we have Fivetran, and it has its internal monitoring; why would we need another solution to monitor these pipelines?” Consider this: we had a case where Fivetran was updating a specific row in the 3T table, and it was updating 100k rows a day for a week. That had never happened before. Fivetran did not consider this as any kind of new data insertion, while the client was perplexed by this unexpected behavior in their business-critical table. The only place they saw this update was Masthead. Let me know if you have thoughts about pipeline observability. I’d be happy to chat about it. Also, if you have any other stories about how you have built something amazing using data, I’d be happy to host you on our podcast with Scott Hirleman — Straight Data Talk.





