Companies have experienced such turbulence over the past three years that despite the continued uncertainty as to whether we’re actually in a recession, many are now actively preparing for one with layoffs and cost-cutting measures across the board. While layoffs are one of the most significant and obvious cost-cutting options, economic uncertainty also influences the way companies want to spend their dollars on cloud services.
Both SMBs and large enterprises have realized an opportunity to control continuously escalating cloud costs.
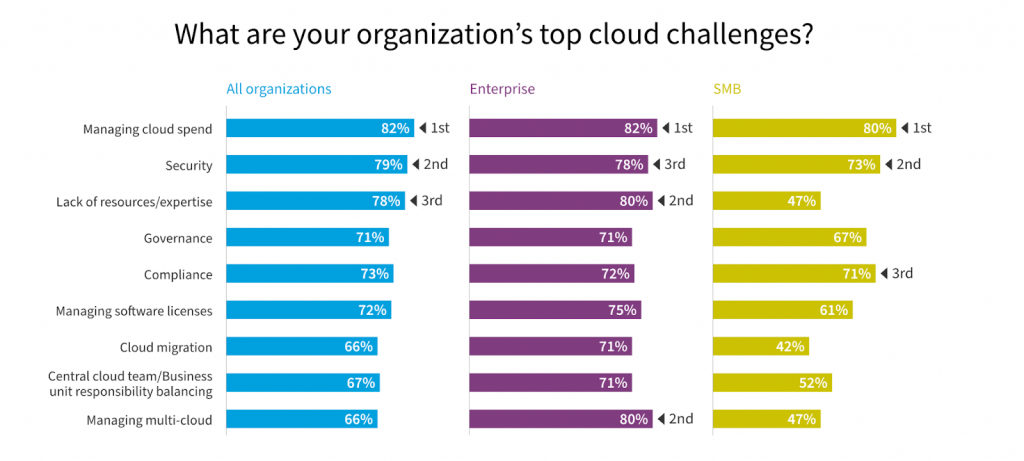
The 2023 State of Cloud Report from Flexera shows that, for the first time in a decade, organizations of different sizes state to prioritize data cost control efforts over security.
It’s no wonder this business concern has translated into tangible growth in end user spending on public cloud services. Gartner predicts that cloud expenditures will grow at an annual rate of 21.7%, reaching a staggering $597.3 billion in 2023, a significant leap from $491 billion in 2022.
In an effort to control constantly growing cloud costs, many organizations have already implemented or plan to build mature data FinOps practices.
Data FinOps enables companies to maximize their cloud investment. While various cloud platforms may require different strategies for managing costs, in this article, I focus on the specific practices that data engineers working with Google Cloud and Google BigQuery should prioritize when it comes to their day-to-day tasks and maintenance responsibilities.
There are three areas you should tackle:
- Storage
- On-demand use (user consumption)
- Optimization of pipelines, models, and ETL costs
1.Optimize Storage usage
Storage in Google BigQuery is not necessarily the largest cost component, and focusing solely on it may end up costing you more in time invested compared to annual spending on storage itself. However, it is essential to strike a balance based on the volume of data that the business needs to process. For instance, if your business deals with petabytes of data (stored in Google BigQuery) on a monthly basis, we highly recommend exploring storage optimization techniques.
1.1 Set table expiration times
First and foremost, Google BigQuery offers two storage billing options that vary depending on the region. Here is the billing breakdown based on the modified event of the tables in the US region (set by default):
- $0.02/GB for active storage, which includes tables or table partitions that have been modified within the last 90 days.
- $0.01/GB for long-term storage of data that has not been modified within the last 90 days.
Consider the prices above while setting your table expiration times, which are, basically, the lifetimes for your tables. You can effectively manage Google Cloud storage costs by defining expiration times for your tables, partitions, and datasets.
A recommended best practice is to set expiration times for tables that are not used in the long term, and even for datasets. Additionally, you can specify an expiration time for partitions based on either the ingestion of time or a time-unit column, in which BigQuery automatically puts the data into the correct partition, based on the time values in the column. Partitioning setting applies to all partitions within the table but is calculated independently for each partition.
Finding the right balance between value created and effort expended is crucial. At one company I worked at, we implemented table expiration times for temporary data stored in our cloud environment. By setting the expiration time to just three days for data that was no longer in use, our team managed to save approximately $3,000 monthly and $36,000 annually, even though we were a relatively small startup. However, it is important to have a deep understanding of the business domain and how data is used within the business when making such decisions.
1.2 Clean up your storage
It is essential to have a clear understanding of what data is actively being used and what data is no longer in use. However, this doesn’t necessarily mean you have to delete unused data; you can simply move it to cloud storage.
For instance, at Masthead, one of our projects successfully achieved a 30% reduction in Google BigQuery storage costs by identifying tables that were no longer used in the business and transferring them to cloud storage for archival purposes. This approach allows you to retain data for future reference while optimizing storage costs in Google BigQuery.
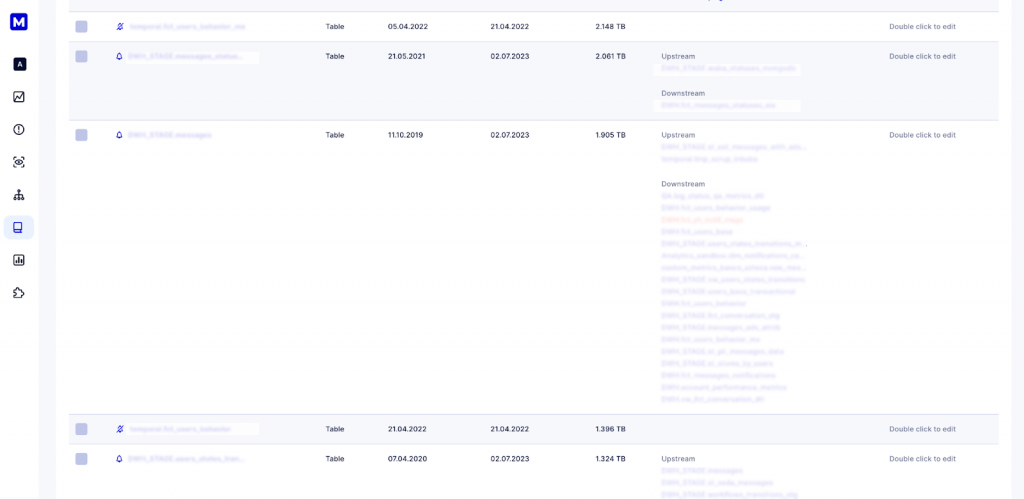
Above, you can see a page from the Masthead Data Dictionary tab, which is sorted based on table size. It indicates numerous tables sized over 1TB that have not been updated for over a year and have no automated jobs or models running that include them.
Before moving further, you should make a significant conceptual decision: Which billing model should your data team use? There are two options:
- On-demand pricing: Pay for the number of bytes processed by each query.
- Editions pricing: Pay as you go for data measured in slots. (This model replaced the flat-rate pricing model on July 5, 2023.)
It’s important to note that billing options vary by region.
The billing model is crucial, as it can be optimized for the data behavior in your business. It’s worth mentioning that you can choose different billing models for different projects in Google Cloud. Essentially, you can run pipelines in one project and control your spending by estimating how many slots they will consume. You can read more about how to set it up here. For ad-hoc user queries where consumption is not that high, you can utilize on-demand pricing.
2. Optimize on-demand usage of Google BigQuery.
In this section, we are talking about people querying data ad-hoc to answer their business inquiries.
2.1 No Select [*] policy
Make sure all users that have access to Google BigQuery are familiar with the “No Select [*] policy.” I’ve run into a few cases where data professionals shared stories of how non-tech folks did a single query that cost their organization over $20K.
To ensure this does not happen in your organization, educate users that have access to BigQuery and ensure you have limited query costs by restricting the number of bytes billed.
2.2. Partitioning and clustering
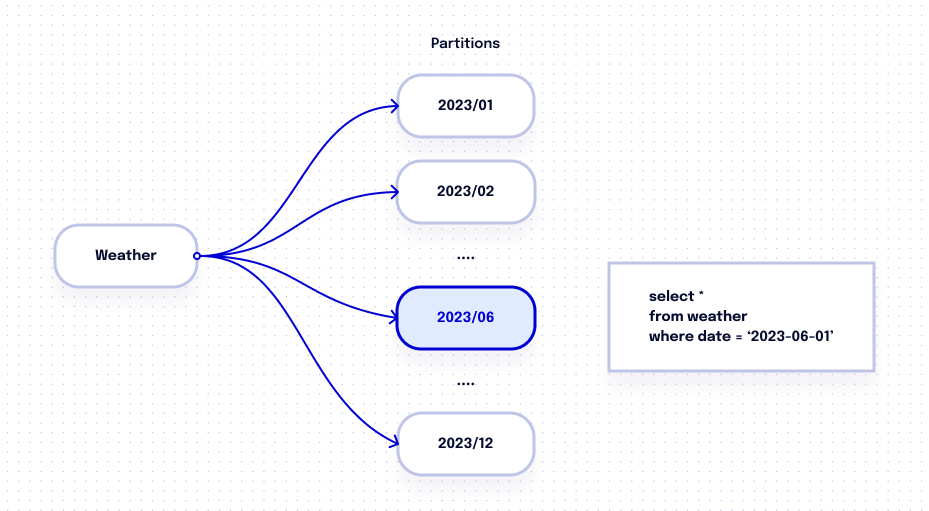
Partitioning provides multiple benefits, including reduced costs for query processing and performance improvements. One way to partition a table is by utilizing ingestion time or any timestamp and date column. Granularity options for partitioning can be set to daily, hourly, monthly, or yearly. To optimize performance for large tables, it is advisable to implement the necessary partition filters, which will compel users to minimize the volume of scanned data.
For instance, if you’re interested in retrieving weather information for June 2023, BigQuery will only scan data within the June partition. As a result, you will only incur costs for scanning data stored within that specific partition rather than for scanning the entire table. This partitioning strategy allows for more targeted and cost-effective data retrieval based on specific time intervals.
In addition, you have the option to cluster your table by up to four columns. When you specify the column order, BigQuery organizes data within each partition accordingly. As a result, when your query involves searching within these clustered columns, BigQuery optimizes the scanning process and only accesses relevant data blocks within the partition. Clustering helps enhance query performance by reducing the amount of data that needs to be processed along with the resulting costs.
Let’s consider a scenario where we enhance the weather table by adding three clustering fields: date, province, and city. Now, suppose you want to search for weather data specifically for Toronto in the month of June. With the clustering configuration in place, BigQuery optimizes the query by scanning only the relevant partition and the limited data blocks where Canadian weather data is stored. This approach significantly reduces the amount of data that needs to be processed, resulting in drastically improved query performance and cost efficiency.
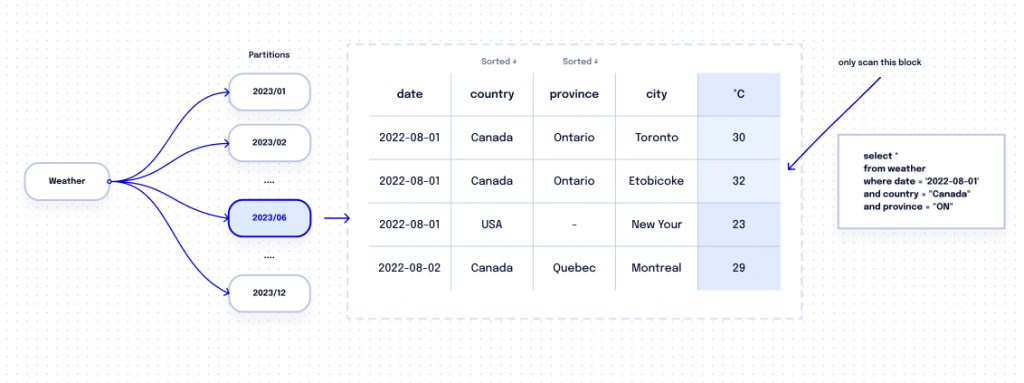
Implementing this approach brings two advantages: faster query performance and lower costs.
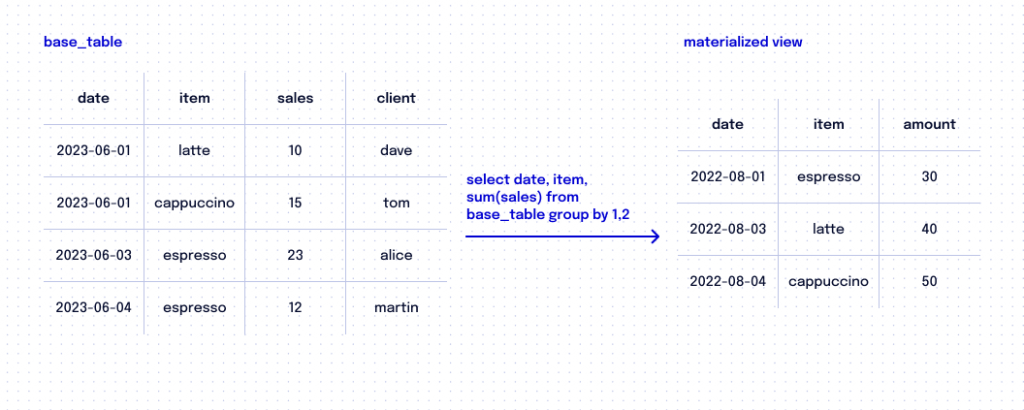
2.3 Lean on Materialized Views
Master the materialized view, which is the database object that contains the results of a query and can be accessed regularly. Repeating the same queries for commonly asked questions is expensive. To tackle this, BigQuery provides materialized views that consolidate data into aggregated fact tables. This saves money by avoiding redundant queries and improves query efficiency.
Instead of fetching data from the original tables, materialized views directly analyze changes made to the underlying tables to provide up-to-date results. This approach is faster and requires scanning less data compared to querying the base tables every time.
3. Pipelines, models & ETL cost optimization.
Solutions running in your cloud contribute to cloud computing costs. When we start working with data teams at Masthead, one of the things we mention, regardless of the industry and the company’s scale, is that data teams may not necessarily know how many pipelines are in their environment. For example, we are working with a company that has over 30,000 BigQuery assets across multiple projects and over 1,400 pipelines running in their system. Yet there are only three data engineers supporting the entire data environment, including data ingestion and data modeling. There is also another company with just over 10,000 assets and 200 pipelines and models in a single Google BigQuery project. They have a remote team of 10 data engineers working in different time zones. Still, understanding and owning pipelines and models — and simply knowing what data is in use — is a challenge.
3.1 First and foremost, use incremental table updates
When building a pipeline, you need to consider data ingestion into Google BigQuery. If a table is small, you can easily reload the entire table regularly. However, for large tables, it’s not practical to refresh the entire table every time due to the high cost and the long time it takes. In such cases, a common practice is to perform incremental updates, which means only updating specific parts of the table that have changed. This approach saves time and resources while ensuring the table stays up to date.
Let’s assume that Table A gets new records added every day. To keep Table B up to date, you have a daily query that captures changes to Table A and updates Table B to reflect them. In this case, doing a full refresh of Table B would be a waste of money because the initial data from Table B hasn’t changed. By focusing on capturing changes to Table A, you can save money and resources while making sure Table B has the most recent data.
One way to handle this situation is by using a reloading window, which is a timeframe for table update that ensures you don’t miss any data from the source table (Table A). For instance, let’s consider a reloading window of three days. Every day, a query is run to select data from the past three-days from Table A. This selected data is then stored in either a Common Table Expression (CTE) or a staging table.
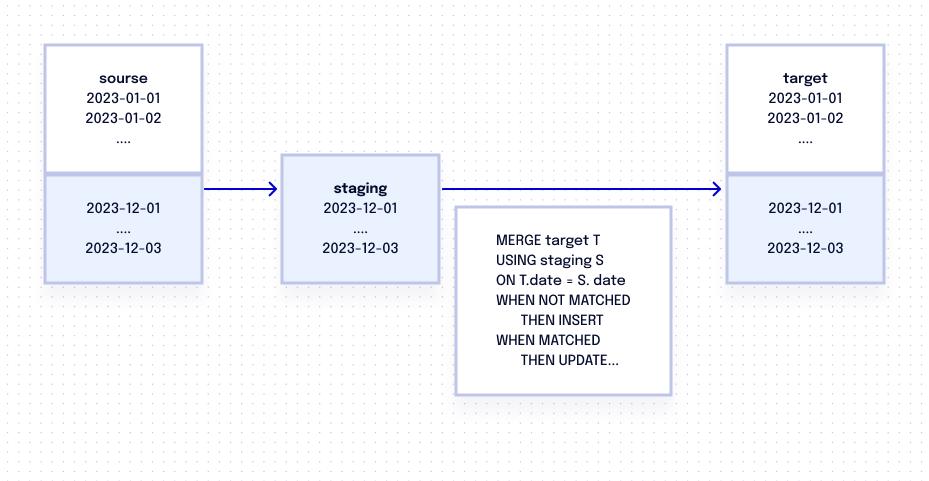
Once the data is stored, the query employs a MERGE statement to update the target table (Table B). The MERGE statement operates as follows: If the staging table contains records with a date that isn’t already present in Table B, it inserts those records. If the date already exists in Table B, the “update” operation simply overwrites Table B with the same data it already has.
By implementing a reloading window into your data pipelines, you can reduce the amount of data that needs to be scanned. This approach proves highly beneficial in optimizing data processing and enhancing overall performance.
3.2. Audit your pipelines and model
When we start working with data teams, one of the things we mention to all of our clients, regardless of industry and company size, is that data teams may not necessarily know how many pipelines are in their environment and how they are used.
We encourage every data team, when they start working with Masthead, to answer simple questions such as: Which pipelines and models are in use? Which pipelines and models are obsolete? Who owns each pipeline, and what is the update frequency? Not to mention How much does it cost to run and how much does a particular pipeline contribute to cloud computing costs?
We firmly believe that ensuring data reliability is impossible without proper data management and audits. The functionality we offer at Masthead helps you audit your pipelines and models in Google Cloud, regardless of the solution that runs these pipelines (custom pipelines, dbt, Dataform, Fivetran, etc.). Auditing pipelines and models helps to improve efficiency and uncover pipelines and models that are no longer in use and could be deactivated.
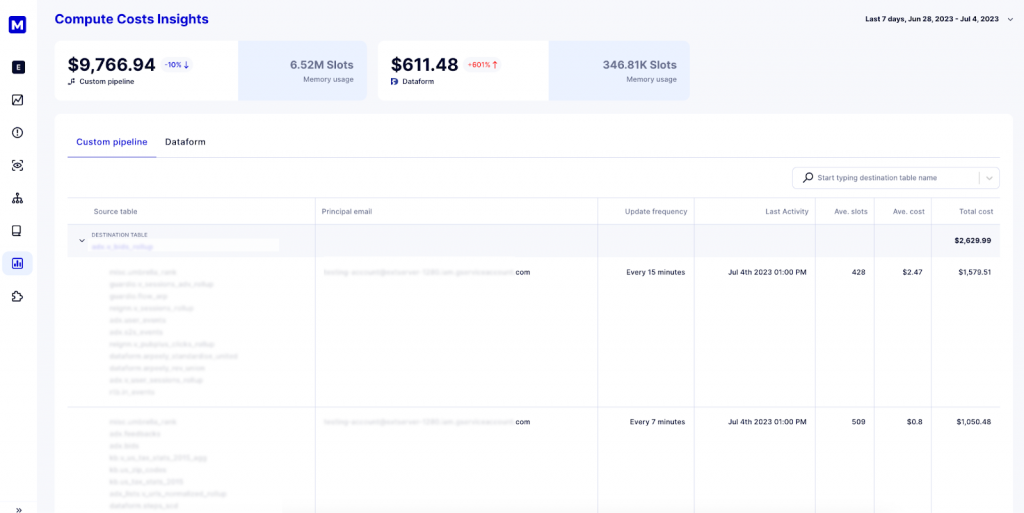
Simply knowing which pipelines update a particular table, which tables are used in data modeling, which service accounts are running them, the frequency of service accounts’ updates, and the total cost of running these pipelines and models within a specific time frame gives the data engineering team control over resources and data infrastructure as well. The low-hanging fruit here is:
- Identifying orphan pipelines and models and discontinuing them.
- Identifying models that can be optimized to run more efficiently (yes, you can use our ChatGPT integration for that too).
- Identifying pipelines/models or dashboards that do not need to run every 10 minutes and can have a reduced update time.
Conclusions
Major cloud providers today compete based on their services, functionality, and ecosystem rather than by engaging in pricing wars. However, their market dominance allows them to dictate the price of their services, as companies have become heavily reliant on particular cloud infrastructure.
In anticipation of economic crises, companies have started re-evaluating their cloud spending and usage to maximize their investments. Within Google BigQuery, data engineers can implement practices to optimize costs and improve efficiency based on specific use cases. There are three key areas to tackle: Google BigQuery storage, ad-hoc usage, and the compute costs associated with running pipelines, models, or ETLs within cloud projects. It is not necessary to implement all three techniques at once; instead, data teams should identify the most relevant practices for their specific needs and gradually implement them according to data use cases in their organizations.




