Spoiler alert: This is a guide on how to enforce schema changes in Google BigQuery leveraging Google Protocol Buffers, aka Protobuf
E-commerce platforms and marketplaces generate data on every step of their operations: inventory, customer orders, pick-up locations, and customer delivery, not to mention marketing channels and integrations.
The requirements for data platforms used in the fast-moving online retail industry vary from business to business, though the baseline is more or less the same:
Flexibility and scalability. The number of events and data sources is growing exponentially, and not just in online retail. That is why flexibility is a basic requirement for data platforms.
Availability is an essential requirement for performance and business continuity. High data platform availability protects you against losing access to mission-critical data, which can result in financial losses and even damage to the reputation of your organization.
Data platform security. Data has become a core asset for companies. Safeguarding data against external corruption or illegal access protects businesses from financial losses and reputation harmful consequences.
Data quality and reliability. This is my favorite one. It’s key because if data engineers cannot guarantee data quality and reliability, data consumers cannot rely on data in their decision-making. This creates a big gap of disbelief in the data-driven culture for the entire company. In the long run, poor data quality can be one of the results of business decline.
The table schema is the vulnerable part. You could govern table schemas using spreadsheets… Or, you could play it smart and leverage the GCP Protocol Buffers, Protobuf for short, which also allows maintaining the schemas up-to-date. Moreover, Protobuf enables you to apply protocols within data pipelines to enforce and control the GBQ table schema.
Understand and Know your Data. Period.
The most common case for online retail is when the largest chunk of business data is produced by IT teams. Data analysts or data science teams use this data to provide insights for businesses and to deliver highly personalized customer services. The majority of today’s systems utilize the microservice architecture. As a rule, each individual microservice has its own decoupled data source. Its architecture is set up to deliver data through real-time messaging channels, such as GCP Pub/Sub or Amazon SQS. Other major channels for online retail include mobile app and website data streams, as well as third-party service webhooks (FB ads, Google Ads, Survey Monkey forms, etc.). The latter can provide both real-time and batch delivery data.
Why Does Table Schema Matter?
Data source owners (IT teams or third-party service providers) can push changes to their data formats without communicating it to data engineers or data analyst teams. At best, there will be a Slack notification at 4 pm Friday night, the one no one ever gets to read.
To safeguard the database table schema in GBQ, it’s crucial that you define a data contract early on, and use it for sending and receiving data through data pipelines. With GCP, I recommend using Pub/Sub to process all incoming messages disregarding the source (internal data or third-party data). It gives you the opportunity to resend all messages and therefore restore data in case of an outage. To control your data schema, you need to specify the data processing logic in protobuf.
How to Embed Protobuf in Your Data Ingestion Processes
First, you need to define field categories for your BigQuery tables in the protobuf protocol. To do this, you need to retrieve table column names through the GCP Data Catalog. The schema you get through Data Catalog will be a benchmark for you to access and control the table schemas. Second, you need to enable the schema registry, which is a protobuf descriptor file that should be hosted in your Cloud Storage. You can leverage CI/CD tools embedded in Gitlab or Github to build and push schema to the registry. It does not matter what ETL tool you use (Dataflow, dbt, etc.) — it can pick up the schema from the registry and create a corresponding GBQ table (if one does not exist yet) before writing data to it.
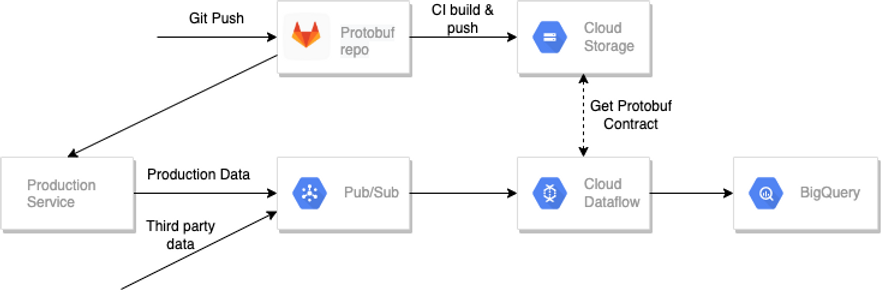
If you need to add a new data source to stream data into GBQ, you only need to push a new protobuf schema to the GitLab or Github repository.
Protobuf Limitations and How to Overcome Them
Imagine a scenario where the IT team drops a field from one of the tables in their production data source. They continue pushing data into the data team’s environment, but the field is not there anymore.
You may ask, ‘Will the protobuf help me to secure from this kind of situations?’ The answer is, Not really, because the IT team can update the contract on their end only. The changes won’t apply to the data team’s contract. If the IT team drops the field and the data team doesn’t update their contract, one of the two things happens:
- If the dropped field is nullable in the GBQ table schema, the data team will start getting ‘null’ values for the corresponding field in their GBQ tables. The job will run without reported errors and who knows how long it will take to discover what’s happened.2. If the dropped field is not nullable, the entire job will fail. To catch the error faster, it is recommended that you have job status monitoring for your pipelines in place, such as Dataflow monitoring or GCP cloud monitoring. Monitoring your pipelines will help you detect the issue faster.
The bottom line is that Protobuf helps to control and manage data schemas, but there is still a high probability for an issue to slip in. There is no silver bullet, but there’s an effective remedy. At Masthead, we’ve built a solution that helps you catch schema changes without data engineers spending hours on endless meetings creating protocols and building monitors for data pipelines, although we still highly recommend having those in place. Masthead integrates with your GBQ and catches any schema changes in real time. Once any field that changed has been ingested, you will get an alert in real-time. This will save you time on figuring out what went wrong. If the field is not nullable and the job fails, you’ll instantly get a notification packed with details on the problem. If the field is nullable, Masthead will see an increase in the percentage of nulls for this very field, which will be also treated as an anomaly.




