Data engineers working with complex BigQuery-based data platforms and environments face numerous challenges due to the overwhelming number of processes that need to be managed manually or kept under control. Unit testing, CI/CD, pull request validation, continuous deployment – all these workflows (and many more) require much manual work and deliberate planning. Otherwise, you’re threatened with failing some critical data jobs, leading to low-quality data, mounting BigQuery costs, security breaches, and even turning your data environment into a complete mess. A certain level of automation and assistance in building and running BigQuery functions will definitely come in handy.
BigFunctions is a framework that provides exactly this kind of automation. It assists data engineers by providing them with 100+ open-source functions that are ready to go. BigFunctions was released by Paul Marcombes, a data analyst with around 10 years of domain experience and a founder of a large community of proactive and ingenious data analysts and engineers. Paul has created BigFunctions to help businesses build a governed catalog of functions on top of BigQuery, instantly getting more value from data.
BigFunctions enables a data team to build a governed catalog of BigQuery functions, known as User Defined Functions. These functions allow such teams to extend BigQuery functionality, improve the reusability of BigQuery queries, and ensure consistent business logic across a company’s analytical operations.
Why is BigFunctions Useful to Data Engineers?
Without further ado, let’s delve into the hot properties of BigFunctions making this tool so attractive for data engineers.
1. BigFunctions offers a vast list of ready-to-go open-source functions
The BigFunctions framework simplifies the lives of data engineers by providing them with a rich catalog of open-source functions. Currently, the catalog includes more than 100 ready-to-use functions divided into different categories, such as AI operations, data extraction, data transformation, notification, data export, etc. The list of these functions is constantly expanding, as the BigFunctions community keeps growing. The functions available in this catalog help data engineers save time dramatically, as there’s no need to create custom functions for different tasks, both regular and complex.
2. BigFunctions offers you great flexibility in creating custom functions
You can easily create new user-defined functions (UDFs) and add them to the BigFunctions library. UDFs are created with SQL expressions or JavaScript code. BigFunctions offers great flexibility in terms of defining functions and modifying the existing ones. With its dynamic query generation, convenient interface, modular architecture, and support for advanced features, BigFunctions allows data engineers to create queries tailored to the most unique cases. You can also create persistent UDFs that are reused across multiple queries or temporary functions that only exist in the the scope of a single query.
3. BigFunctions offers a convenient CLI
BigFunctions offers a bigfun CLI (command-line interface) that makes development, testing, deployment, documentation, and monitoring very convenient. The bigfun CLI is easy to install, and it offers very concise and understandable command syntax.
4. BigFunctions is very easy to deploy
There is no need to install BigFunctions from your BigQuery project. The point is that all BigFunctions are represented by a ‘yaml’ file in the bigfunctions folder of the GitHub repo. To automatically deploy BigFunctions in your project, run several simple SQL calls from your GCP project, and that’s all!
Mastering BigFunctions: Features and Best Practices for Data Engineers
The list of library features and best practices for the efficient use of BigFunctions is constantly expanding. Here we will provide several essential tips and best practices on how to use this framework efficiently, embracing the innovation in data.
Creating and deploying functions
In BigFunctions, all functions are defined as yaml files under the bigfunctions folder. All that a data engineer has to do to create such a function is to download an existing yaml file from the unytics/bigfunctions Github repo. Each file can be updated to suit a particular data engineer’s needs.
Once a function is created, a data engineer can follow a rather simple pattern to deploy this function.
- Make sure to install the gcloud command on your computer
- Activate the application-default account with gcloud auth application-default login. Log into your Google account once a browser window opens. After that, bigfun will use your oauth’d credentials to connect to BigQuery through the BigQuery Python client!
- The next step involves creating a DATASET where you will deploy the function. You should have permission to edit data in this DATASET. It should also belong to a PROJECT in which you have permission to run BigQuery queries.
Upon completing these simple steps, you can easily deploy the function, such as is_email_valid defined in bigfunctions/is_email_valid.yaml yaml file by running the following command:

The first time you run this command it will ask for PROJECT and DATASET. Input information that will be written to the config.yaml file in the current directory. As a result, you won’t be asked for these inputs again.
Deploying javascript functions depending on npm packages
You can deploy such a function be following this path:
- You should install each npm package on your machine and bundle it into one file. Make sure to install nodejs for this task.
- The bundled js file will be uploaded into a cloud storage bucket.You should have write access to this bundle, and its name must be provided in the config.yaml file in a variable named bucket_js_dependencies. Be sure to provide all users of your functions with read access to the bucket.
To deploy the function render_template defined in bigfunctions/render_template.yaml yaml file by running:

Deploying a remote function with BigFunctions
These are the several requirements you should follow for such a deployment:
- You must have permission to deploy a Cloud Run service in your PROJECT.
- Make sure that you are logged in with gcloud with a call: gcloud auth login. Then, log into your Google account in a browser window that will open. This is essential because gcloud CLI is used directly to deploy the service.
- To link BigQuery with the Cloud Run service a BigQuery Remote Connection should be created. Be sure to use BigQuery Connection Admin or BigQuery Admin roles to have permission for creating such a connection.
- Google will automatically create a service account along with the BigQuery Remote Connection. This service account of the remote connection will be used to invoke the Cloud Run service. Be sure to use the role roles/run.admin as it offers you permission to authorize this service account to invoke the Cloud Run service.
To deploy the function faker defined in the bigfunctions/faker.yaml yaml file, run:

Retrieving data from the public_repo into the destination_dataset
BigFunctions allows you to easily retrieve data in raw format in tables from the public_repo into the destination_dataset using GitHub Airbyte Connector with Airbyte-Serverless. Create the destination_dataset and give dataEditor access to bigfunction@bigfunctions.iam.gserviceaccount.com before calling this function. To do this, execute:
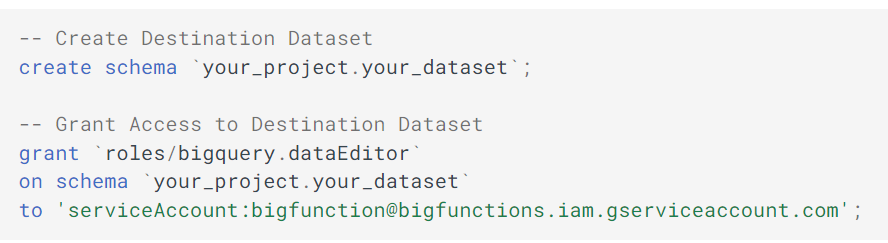
While or after this command is running, you can explore logs in the table your_project.your_dataset._airbyte_logs
Conclusions
BigFunctions is a certain way to supercharge BigQuery by offering a variety of off-the-shelf functions and a convenient interface, BigFunctions proves to have a rich potential for simplifying basic data engineering operations both here and now and in the long run. The framework and its ecosystem are constantly developing. Make sure to keep an eye on all of its innovations and best practices to boost your data procedures, automate manual processes for your data team, and even contribute to the rapid growth of the data engineering ecosystem.





