Thanks to C2C Global, I got an opportunity to have an insightful conversation with Amy Raygada. A data solution integration manager with over 13 years of domain expertise, she is known as a great advocate for a data mesh. Throughout her rich career, Amy helped many companies, including Micro Focus, SMG, Epam, trivago, BayWa r.e., transform their data practices and embrace the vision of data as a product. Our speaker is also a founder of COSMODATA, a mentorship and coaching initiative aimed at training business executives to drive business growth by aligning data strategy with the corporate vision. I had the pleasure of hearing her arguments and getting meaningful insights into the concept of data mesh, as well as its real-life implementations.
The Benefits and the Basics of a Data Mesh
Data mesh is a buzzword that is always around in the modern data domain. Amy highlights the main reasons behind such a high demand for data mesh. This approach can bring businesses many benefits in terms of managing and leveraging data, with the most important ones being:
- Scalability that goes with an opportunity to break down large data structures for easier growth
- Decentralization of data, which allows teams to manage their own data efficiently
- Improved agility, faster innovation, and adaptability to change
- Simplified handling of complex data structures
- Data quality boost achieved through raising data awareness among the stakeholders involved
- Enhanced collaboration across different company departments
- Domain-level adaptability that boosts data governance
With all these benefits built on the top of a data platform, businesses take a solid step toward the lucrative notion of a data-driven company.
When and Why Do You Need a Data Mesh?
But does data mesh fit all the companies?
Data mesh is very beneficial to large enterprises dealing with high data loads managed by one big data team or several smaller teams, heterogeneous data infrastructure, and a variety of silos across the company .
- Data mesh brings many benefits to medium-sized companies with one large data team, no data governance and ownership, and an experience of rapid data growth .
- Even if a small business is far from having full-fledged data structures and teams, adopting some data mesh principles, such as data governance best practices or data-as-a-product principles, will be beneficial to this company as it grows.
Our speaker intentionally avoids the conventional definition of a data mesh. Instead, she explains the concept through its value. According to Amy, a data mesh can take quite different forms in different companies, but its primary goal is to help a business make data-driven decisions.
While explaining the ideal scenario, Amy mentions that a data mesh “…allows anyone in the company, it doesn’t matter if a technical or a business person, to be able to access data and understand how to bring benefit out of it.”
Data Mesh Implementation
The next question that Amy explores is the starting point for implementing a data mesh. If a company has only one data engineer and a few data tables, there are just too few assets to create a data mesh. However, even in such cases, it would be beneficial to start building its foundations, such as access controls and a data-as-a-product concept. Federated data governance also means a lot because it defines both processes (project organization policies and data checks, etc.) and the mentality (data ownership, approach to data privacy, etc.) in how different stakeholders approach and manage the data.
Data mesh depends on several factors, namely:
- The number of people in the organization
- Organization set-up (team and infrastructure)
- Data maturity level
- Technical company goals.
Certain ways to achieve a data mesh are data democratization, creating systems and adopting tools, talking about necessary data with ease, and making data-driven decisions. However, in reality, embracing all these practices and achieving a data mesh is quite a challenge. According to Amy, the top words that business stakeholders mention while thinking of a journey to a data mesh are “complex” and “messy.”
A Journey to Data Mesh: A Real-Life Success Story
Amy proceeds with a use case from her professional practices to illustrate the long journey to a data mesh. She was working in a large e-commerce organization operating in different industries. The company was going through a merger, which uncovered many issues with the inconsistency of systems. Amy took a critical part in the initiative of creating a single data infrastructure. At first, it was a rather straightforward system based on SQL Server on-premises. Its architecture is illustrated in the image below.
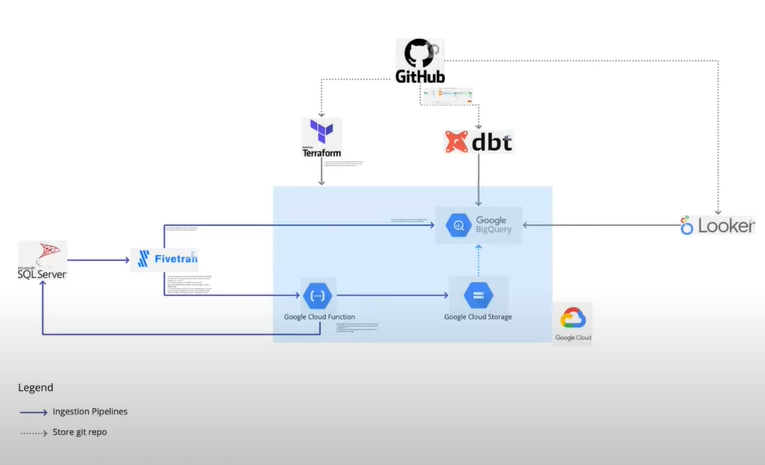
As data engineers kept adding new components to the system to make it work, everything was turning into a mess without features for tracking changes and some other critical functionality. At that point, Amy and the team of data engineers were not even thinking about the concept of data mesh. Their primary goal was just making things work. Driven by the need to update and restructure their data infrastructure, Amy and the team moved it to Google Cloud and added several new components, such as the Atlan data catalog. Basically, it was a lift-and-shift migration that preserved the complexities of the system’s on-premises predecessor.
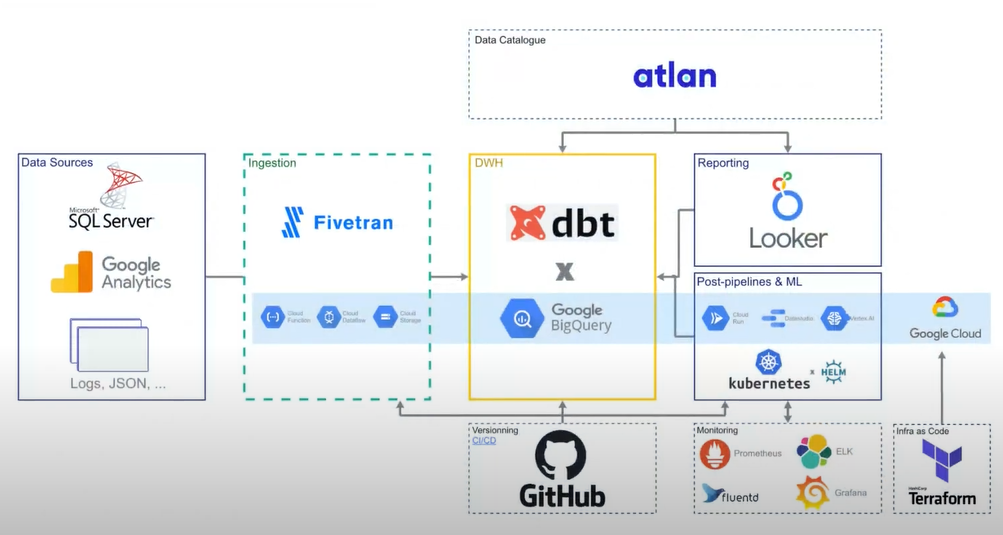
The main problems were the great diversity of data sources within the company, poor data quality, lack of communication between the departments, and a great diversity of metrics (for example, the company was dealing with five different types of revenue). In addition, there was a huge backlog of pipelines and reports. The entire responsibility for managing it laid on the shoulders of the data team, which had many challenges with processing and monitoring all the data products. What was the outcome? Slow and inefficient system and all the blame is put on the data team.
The company hired an architect to improve its data architecture. Some solutions worked, as, for example, the introduction of Dataflow improved the efficiency of data streaming. However, the deeper problems lay in the stakeholders’ approach to data. The company was using a monolithic architecture without any data ownership and without clear communication among domain specialists. In such conditions, domain-driven decentralization of the data architecture had to become the ultimate solution. To set the foundation for such an approach, the team distinguished the key directions:
- Continuous event-driven data motion
- Improved data governance and data standards
- Delegating the responsibility for data not only to the data team but also to business people
- Self-service tooling
Such principles allowed the company to achieve a domain-driven data architecture where data is really put into use by corresponding stakeholders.
Dealing with the resistance of the representatives from different domains, data teams started working on federated computational governance with more discoverable datasets, clear ownership policies, and efficient deletion of data products. The new data architecture is constantly expanding, as various domain teams start taking ownership and responsibility for the corresponding data products. Now data quality is everyone’s responsibility, while data contracts define the rules for creating, deleting, and modifying the data products. Once any change to a dataset or any other data product is introduced by a particular domain specialist, there has to be a pull request notifying all the users who have subscribed to a data contract and asking them for the approval.The complete flow is displayed on the image below:
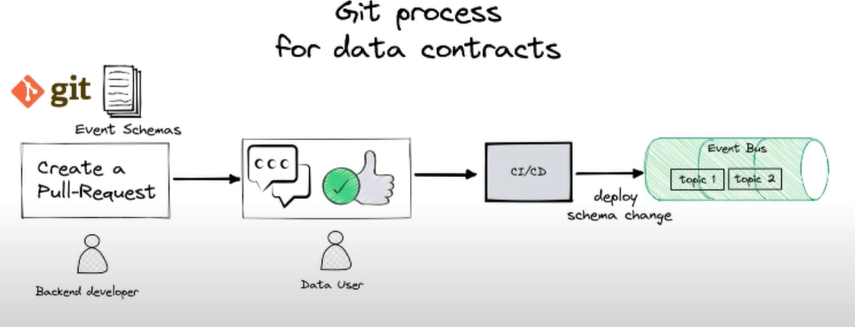
Consequently, the company embraced the following product development lifecycle:
1) Domain needs affect a user
2) A user declares the need
3) A candidate for a product satisfying this need is created
4) A product is validated
5) A product is implemented
6) A product is tested and deployed.
With such a strict process, people think twice before creating a data product. They ask questions on its need, number of consumers, presence of similar products, etc. This facilitates communication between domain teams, makes each domain team treat their domain data as a product, and facilitates the culture of shared responsibility for data. In such conditions, great savings in GCP compute consumption are just logical outcomes of such a shift in perceiving data.
Conclusions
I must note that the company in which Amy was working still has a long journey to go to achieve excellence in taking value from any data product. However, the transformation that our speaker has started vividly shows her how data mesh principles can transform even the most complex data architecture from a mess into a tangible asset that brings value to the business. According to her, one of the biggest problems here is the resistance of stakeholders who often believe that things work better “the old way.” This has made her, as she calls herself, “a preacher with the Bible of data governance.” There is a wide array of benefits of federated data governance and a data mesh architecture that can be explained theoretically. But Amy admits that nothing promotes these ideas better than successful examples of teams and companies that have managed to revolutionize their data practices by embracing the core values of the data mesh approach.
She is always ready to share her knowledge and real-life data mesh success stories, and we urge you to watch the recording of our webinar to get even more meaningful insights on the value, benefits, and challenges of implementing a data mesh architecture.





