Thanks to C2C Global, I had a very interesting conversation with the one and only, Andrew Jones. This speaker boasts massive expertise in the data domain. A data consultant with many years of hands-on experience and an advocate for data contracts and self-service data platforms, Andrew is also known as the author of one of the industry’s biggest books – “Driving Data Quality with Data Contracts: A comprehensive guide to building reliable, trusted, and effective data platforms.”
During our discussion, Andrew Jones presented his vision of a self-service data platform, the benefits of such an approach, and the intricacies of building such a solution with the Google Cloud Stack.
What Is a Data Platform?
Andrew starts our discussion with a definition of a data platform. According to him, it is a platform that provides features allowing others to autonomously create, manage, and consume data. The main capabilities of such a data platform include:
- Ingestion
- Transformation
- Orchestration
- Data management (backups, data retention, access control, etc.)
Data platforms are often built and maintained by a data platform team that involves a mix of data engineering and platform engineering skills, something that Andrew defines as the evolution of DevOps.
The image below illustrates Andrew’s ideal vision of a data platform as a solution built and managed with the contributions of data engineers, ML engineers, and software engineers.

The output of such a platform is tooling or infrastructure for managing a running diverse operations (orchestration, transformation, etc.) with data. You can use a variety of tools in your data platform. For example, you can apply orchestration tools like Cloud Composer and Airflow, or dbt for data transformation.The key point of such a solution is that it provides ease of use for tooling. Different specialists from different teams can apply a data platform to run various operations with data, for example, to create a dashboard. So, basically, a data platform is like a layer making data accessible to specialists from outside the data team.
Scenario: From Data Accessibility to Data Dependability
Upon explaining the essentials of a data platform, Andrew Jones proceeds with a practical example that highlights typical issues in creating a data platform. He describes a common scenario in which a company faces the evolving data needs of a scaleup. Typically, such an organization will focus on making data accessible, which means building efficient mechanics for getting data out of the system and transferring it into a data warehouse or a data lake in order to get insights. This company might do it by using a database replica, an ELT, or a CDC approach.
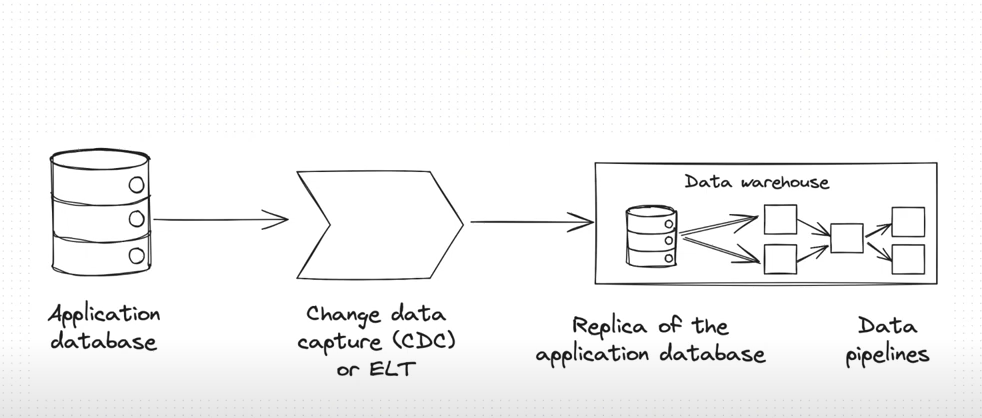
However, there are some common issues pertaining to database replication. In most cases, a database replica is built upon an upstream database, which can have a terminology that is completely different from the company’s business terminology. In other words, the terms used in a database may mean something to the service but not to the business. This creates operational challenges in managing the data and the data platform, especially if we are dealing with a large company that has poor documentation on its data architecture and relies primarily on so-called “tribal knowledge.” Andrew also points out that building solutions on the top of the DB may be unstable and lead to incidents. According to our speaker, it might be impossible to build critical data applications upon the data due to such instability.
Andrew believes that the ultimate solution is doing things at the source. It is important to define things, such as terminology close to where the code is and ensure consistency across the system from the very start. As data changes frequently, it is important for companies to change focus. Andrew states that it is important for companies to change focus from prioritizing data availability to emphasizing the dependability of data.
Our speaker points out that data dependability is a certain way to use data as a competitive advantage helping companies to drive key business processes and power revenue-generating product features.
Andrew Jones provides several tips on how to achieve this data dependability:
- To keep data stable, you need to apply more discipline to data management and especially data creation; a data contract is a vital tool for achieving this level of discipline
- Do not build data applications upon upstream data
- Data producers need to provide data fit for consumption, which means that such data should meet consumer requirements (structure, SLOs, etc.)
- It is important to define clear responsibilities in creating and managing data products.
One more time, Andrew emphasizes that you should focus on its source providing a clear link between the data and its production source. After all, you cannot make the quality of the data in your data products higher than the quality of the data at the source.
It is also important to take the right approach to change management. When a change happens in the source system, most teams focus on remediation activities, such as using different data IDs and changing data pipeline joints. But if you don’t want the issue to happen again, you should start thinking of prevention techniques. It is important to ensure the collaboration of different data teams, which will help you find a new approach to the data pipeline or any other source of the change.
Andrew focuses on the role of software engineers in this process. According to him, a self-service data platform should provide software engineers with an opportunity to introduce changes without involving data teams and breaking downstream applications. Andrew Jones proposes using API (application user interface) that will allow software engineers to introduce changes to the data platform in a way they are comfortable with.
Andrew understands that such a transformation in software engineers’ responsibilities might take time. Previously, software engineers were often unaware of data matters, and now we want them to deal with data. Therefore, it is important to make data-related workflows easy for the engineers, as well as incentivize them. According to Andrew, in his practice, the software engineers’ willingness to collaborate played a crucial role in the project’s success. Another essential factor was that a data team was ready to lower the solution’s complexity bar in order to make it more accessible for the engineering team.
An Example of a Self-service Data Platform
At this point, Andrew Jones proceeds with a more detailed overview of a self-service data platform that he helped to design. Some of the most important features of this solution:
- Software engineers can autonomously create and manage their own data without central review and approval
- These workflows can be handled explicitly, not through CDC
- All data operations are available to the user through a standard interface.
Our goal here is to move away from the database directly and ensure database management through a separate interface. As a result, the data platform becomes an isolated layer for software engineers and data customers.
When it comes to the data platform on which Andrew had been working, these are its essential features:
- The platform is built around data contracts that define the principles of working with data. Jsonnet is used as a configuration language for those contracts. Avro, which is a popular solution for such cases was rejected because software engineers on the described project felt less comfortable with it and Andrew decided to prioritize the engineers’ convenience. Other languages, such as Yaml or Python, can be used for such configuration.
- CI checks are used for change management.
- The platform provides a provision interface, which includes PubSub schemas for data streaming (it was chosen instead of Kafka because PubSub provided enough functionality for this particular project and was very cost-efficient, consuming only 0.85% of the project’s total cloud cost), BigQuery tables, services for access control, backup, data retention, etc.
- Google-provided libraries and some custom libraries are used to write data.
- The platform includes a reporting layer, which includes dbt, Looker, and Dataform.
The image below displays the architecture of such a system.
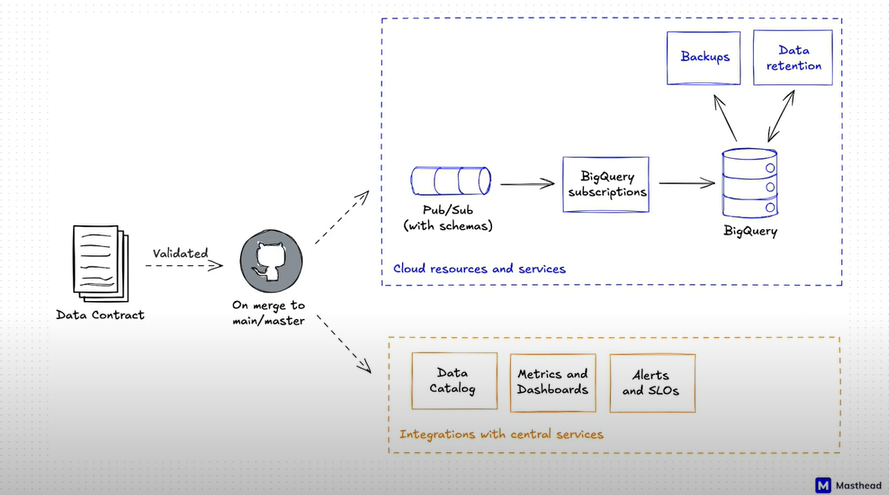
Upon validation, the data contract is delivered to the main/master who merges it to cloud resources and services (oriented primarily on the team that manages the data platform) or to integrations with central services (serving as resources that a data platform team provides to other teams within the organization).
Concluding Remarks
Once Andrew explained his vision of an ideal data platform and emphasized the value of isolated data projects, I decided to provide additional remarks. I presented an example of a company that had a data platform where it was important to spin up a new GCP project every time data consumers needed to isolate data products. This created significant issues with data duplications, as the customer created dozens of similar data projects that were challenging to govern.
Andrew Jones explains that discipline is the key to solving such issues. There should be clarity and discipline in creating data projects, and, ideally, this task should be the responsibility of a single team. In any case, the organization of data projects and the entire data platform architecture depend on data contracts. No wonder that this concept takes a central place in the methodology for which Andrew Jones advocates.





