1. Should we go from on-demand pricing to slots?
This is a good one. No answer fits all sizes and all businesses. However, from what we’ve observed if we’re talking about reasonably predictable compute consumption, Editions (slot model) can be a better option. Predictable compute consumption typically includes ETLs and data processing jobs. From our observation, switching ETLs to Editions can lower BigQuery compute costs by 15%, but this largely depends on the company, its data, the complexity of queries, the data stack, and the maturity of the data team.
Tip: Locate all scheduled jobs in one Google Cloud project for tracking purposes. In Google Cloud, the compute pricing model can be chosen at the project level, unlike storage, which is chosen at the dataset level. This will increase the efficiency of the cloud compute resources.
The good thing is that it doesn’t matter which project you take data from and load to; what matters is where the process is running, as this is where the billing will be assigned. In other words, if you take data from project A (with an on-demand BigQuery pricing model) and load it to project B (also with an on-demand pricing model), but you use a job assigned to project C, you’ll be billed for data processing based on project C’s billing model. This is why we suggest that all scheduled/repeated processes be located in a dedicated Google Cloud project set to the Editions billing model.
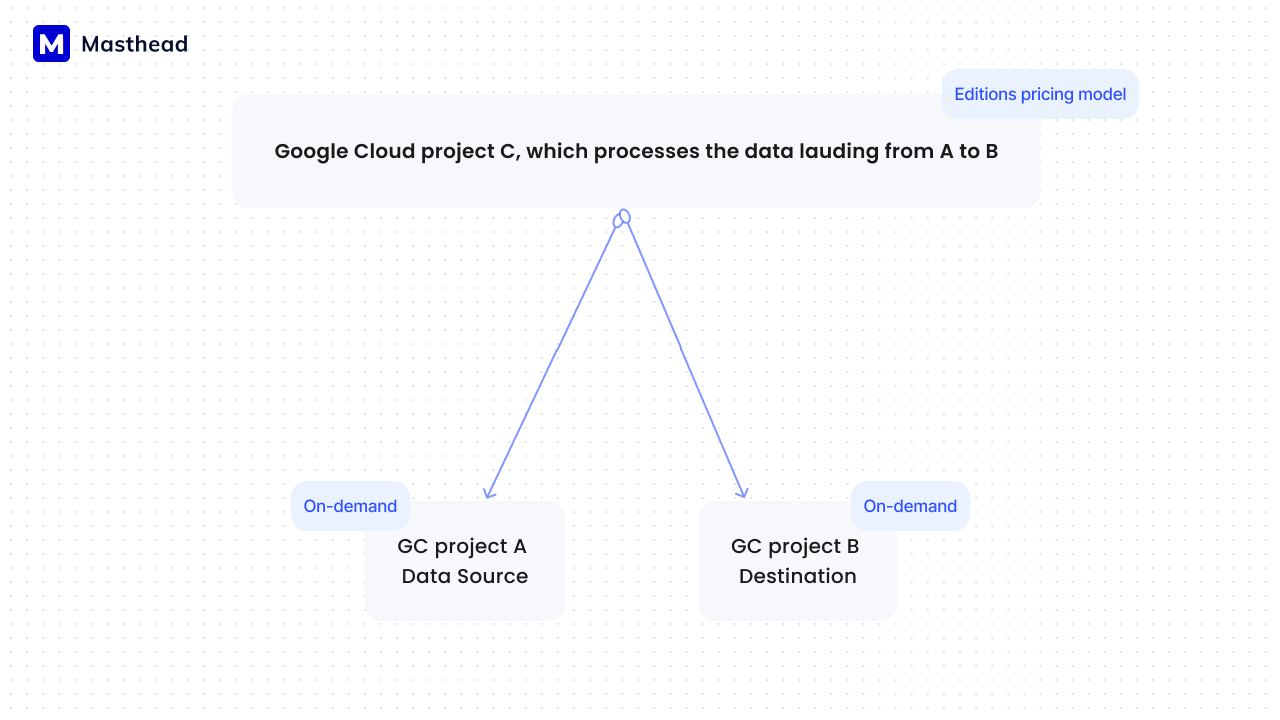
Courtesy of Masthead team
If you still have doubts about whether it is worth it to rearrange everything and switch to editions, talk to us. We have a way to show you the price in editions for all your pipelines.
Another good idea to answer the question of whether it is worth switching to editions is allocating one project and trying it without committing but with a pay-as-you-go format. This will help your team evaluate whether that is the right choice. It’s important to note that you can switch from editions to an on-demand billing model anytime and vice versa.
Here is a short Google BigQuery compute pricing navigation map that will help you orient across available options.
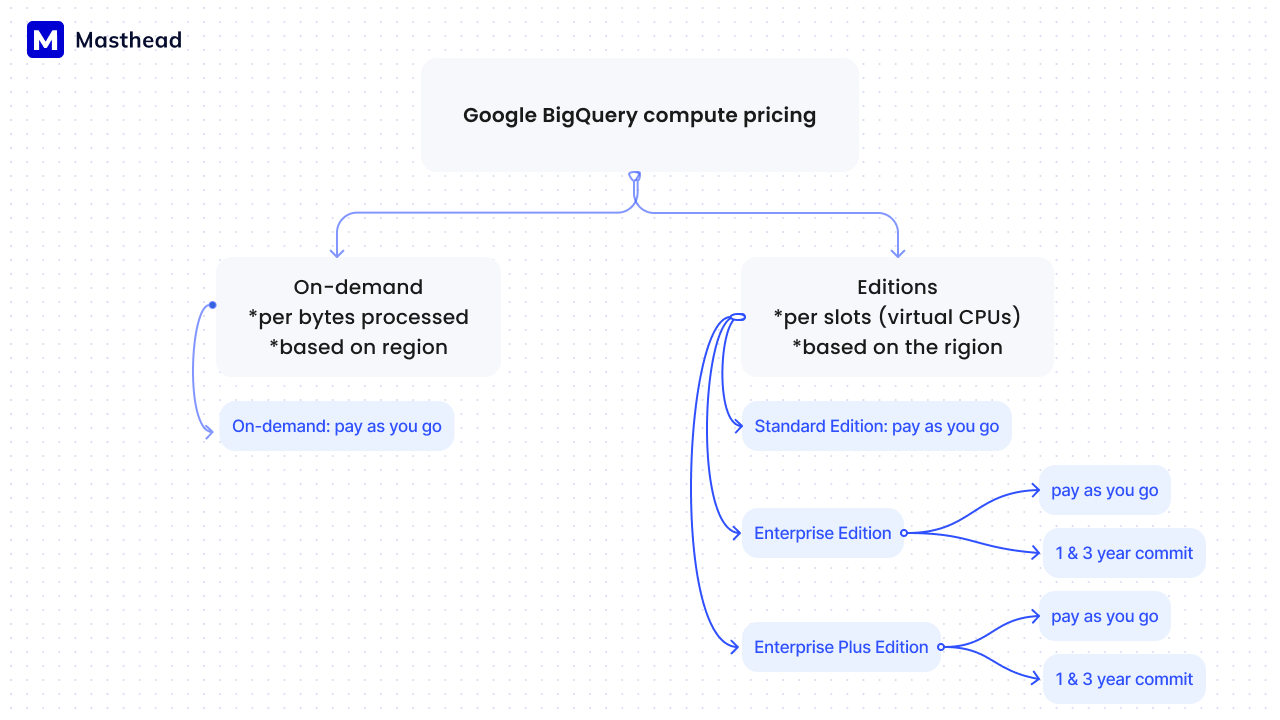
Courtesy of the Masthead team, the prices are subject to change, so we suggest reviewing that directly on the Google Cloud website.
2. Commit or not commit to slots? How do we make a decision?
First of all, I personally think that Google wants you to commit, and they make a pretty good offering. To understand if Editions make sense for your organization, it’s a good idea to test it on a pay-as-you-go basis. I know a few large organizations that did this to evaluate their options better before committing to any offer.
Another hurdle I encountered with some clients is that when you commit to slot reservations, you commit to reservation of the slots in a specific location. If you need to move the compute operations to another location for any reason, it will be considered a different SKU. This means you cannot just switch your reservations to another data region; you would need to purchase separate reservations. However, it’s important to know that using committed reservations doesn’t prevent you from using on-demand Editions and running jobs in a region other than your committed reservations.
But what if the region you purchased reservations from is not available, and you need to transfer your compute to other locations immediately?
This is a good one :). To tackle this issue, the Google Cloud team is working on a feature called Cross-Region Dataset Replication. This allows users to set up automatic replication of a dataset between two different regions or multi-regions. Heads up, this feature is expected to be generally available (GA) by the end of H1 2024. Essentially, when you create a dataset, you also determine which region will store copies of your data.
Still, even if your organization would prefer to have that in place, it is available only in the heist tier of Editions: Enterprise Plus.
However, even if your organization would prefer to have this feature in place, it is available only in the highest tier of Editions: Enterprise Plus.
3. So, are Editions worth it?
Short answer is that one size does not fit all, and it’s not all that shiny and good. Personally, I believe that Editions pricing model based on time and CPU is designed to catch up with the market. Snowflake had this billing model since its launch, and it worked great for them and their customers. Check out my post on that, which was heavily influenced by chatting with Marcin, co-founder of Snowflake.
At Masthead, we hear about a couple of common problems that customers who are using Editions encounter from time to time.
One of the biggest issues is the shortage of slots, or what could be framed as a poor utilization strategy. Often, a bunch of data processes will be scheduled in the morning to ensure data is pulled right at the start of working hours. With slot reservations, teams run into problems when high-load processes are fired off around the same time, consuming more slots than reserved. This results in downtime for some pipelines, retries, longer processing times, and consuming more resources than planned.
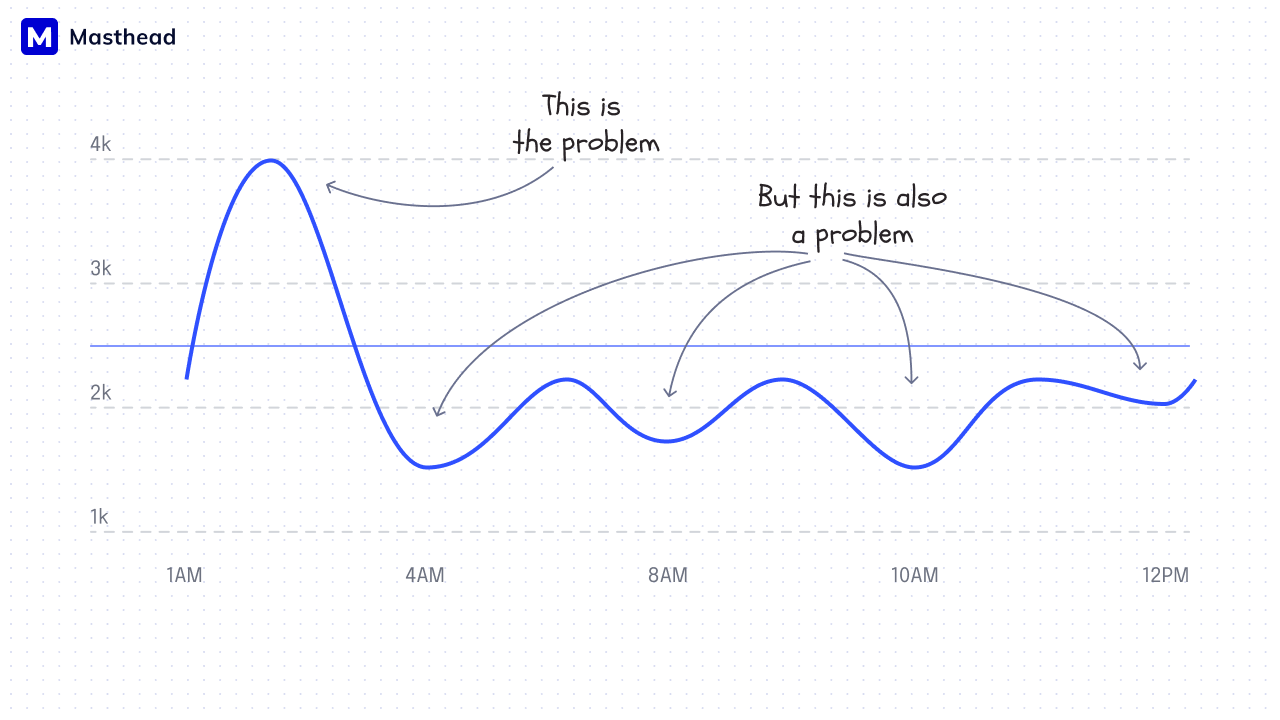
Courtesy of Masthead team
For example, if you purchase 2,000 BigQuery slots, your queries are limited to using 2,000 virtual CPUs at any given time. However, you cannot entirely predict the volume of data processed across all your data sources. Of course, you can reserve more slots to handle your morning data routine, but that’s not always efficient or cost-effective.
Tip: To ensure you benefit from Edition pricing, your data team needs to make sure that processes, especially high-load ones, are evenly distributed over time. This avoids situations where slot consumption spikes simultaneously, leading to long job durations and retries. If you have this problem, don’t hesitate to reach out. We are happy to show you what we are working on at Masthead to address it.
Another problem is the attribution of reserved slots. Google BigQuery reservations are often purchased centrally by a distinct Google Cloud organization for use across the entire organization. The organization commits to reservations, sometimes of several types, and then assigns them to specific Google Cloud projects top down to other projects based on their needs and usage considerations.
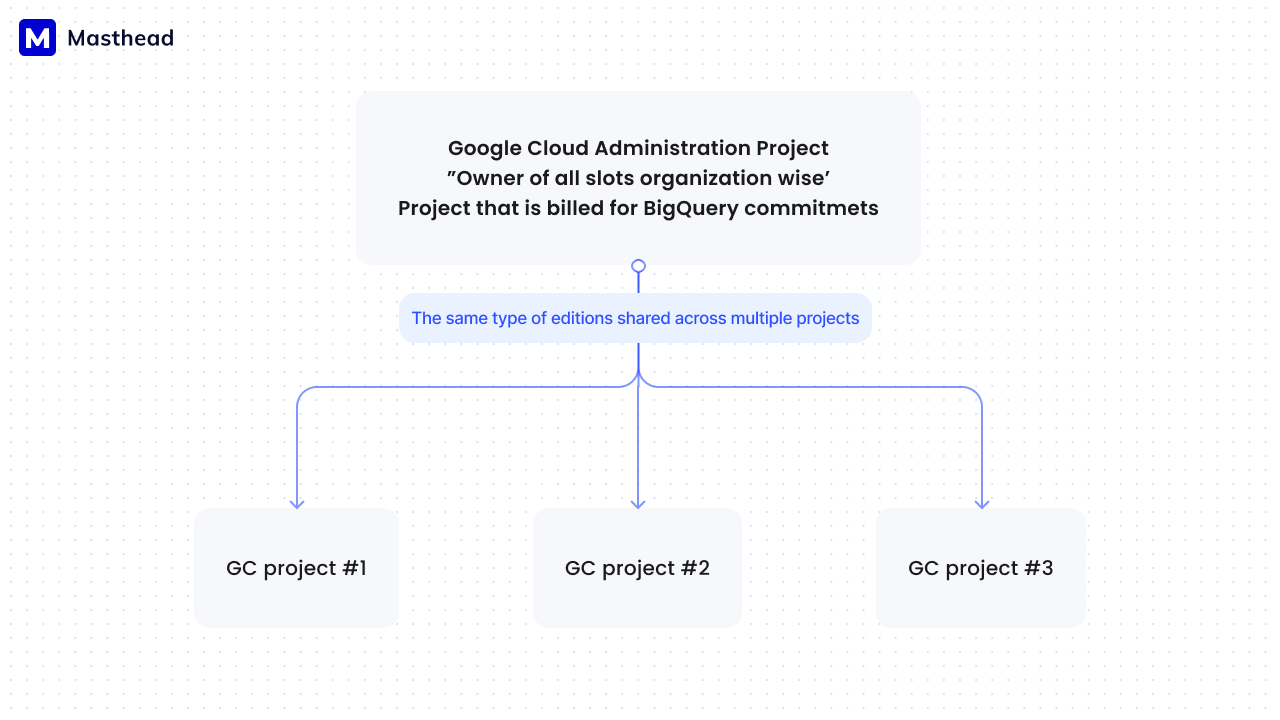
Courtesy of Masthead team
The challenge here is that it’s unclear how many reserved slots must be allocated to a specific project. The finest granularity GCP allows for attributing reservations is at the JOB level, but this level of detail is often not what you’re interested in. Typically, you want to understand how much consumption the pipeline uses within a specific time frame.
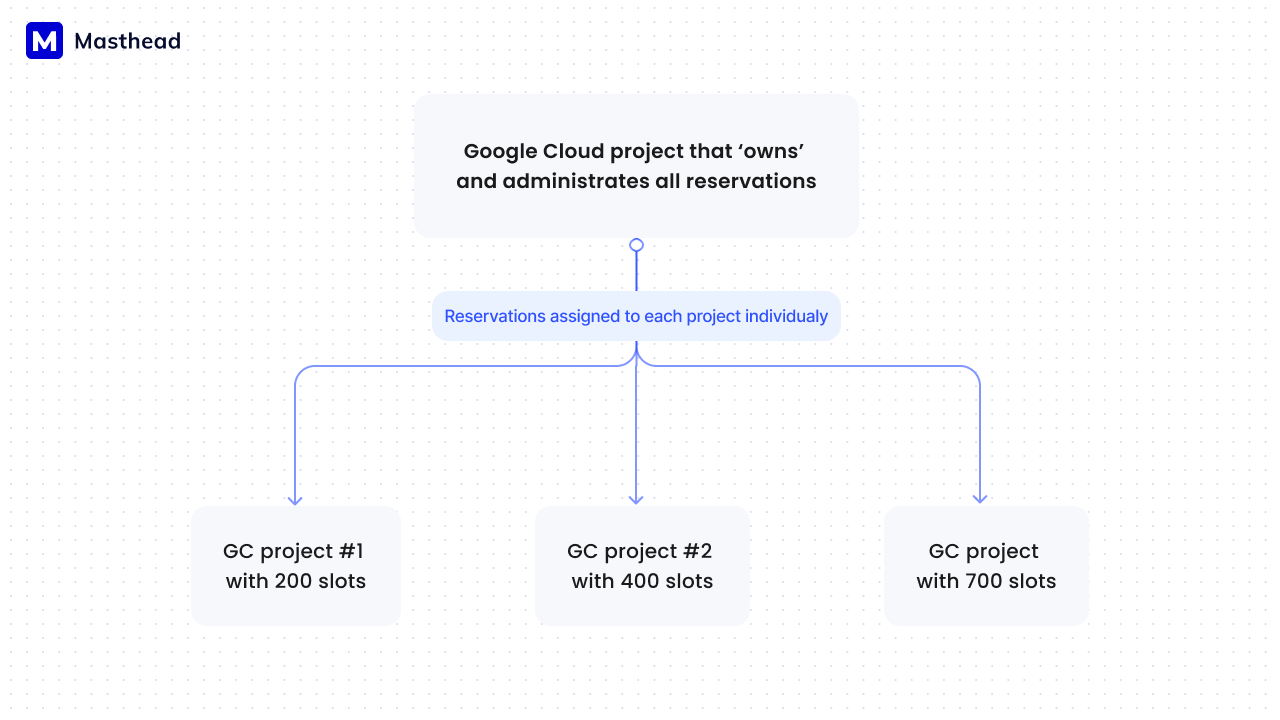
Courtesy of Masthead team
I can’t help myself and have to brag that we handle this at Masthead. At Masthead, we show slot reservation allocation within 30 minutes after deployment. We use retrospective logs to deliver value to our clients. Ping me if you want to learn more about optimizing Google BigQuery costs.





