What differentiates data observability from software observability? Let’s delve into the differences and similarities.
For the past two decades, software observability tools have surged in demand, with notable examples like Datadog, New Relic Splunk assisting software developers in monitoring software applications and infrastructure by logs, metrics, and traces. These products aim to minimize downtime and optimize the performance of software. Subsequently, the tenets of observability extended beyond just software, leading to the rise of data observability as a trusted method for data reliability.
Despite their distinct purposes, both data observability and software observability encompass shared features. We’ll spotlight these commonalities and set the two concepts side-by-side for comparison.
The Evolution of Observability Tools
Observability has evolved beyond just software, finding its niche in the domain of data management ensuring data trustworthiness and reliability.
Why Logs Matter in Observability Solutions Log monitoring sits at the heart of observability tools. With every system event, a corresponding log is generated, detailing:
- What and when was executed in the system
- Duration of the operation
- The executor of the operation
- The operation data source
- The operation’s downstream impact
- Destination tables of any operation
- The compute cost of executed operation.
Software observability tools use log data to identify issues affecting software application performance. On the other hand, while many data observability tools claim to focus on logs, they often use intensive SQL queries. These queries look into table data to check things like data volume and freshness rather than just the logs. In simple terms, despite their claims, many data tools don’t just look at logs but dive deeper, as they request access to read or edit clients’ data using methods that require the ability to run scheduled SQL queries against clients’ data.
Key Differences and Similarities Between Software and Data Observability Tools
Similarities
- Neither should be mistaken for quality assurance testing. While the latter simulates predictable situations, software and data observability tools perpetually monitor for unpredictable data anomalies with infrastructure for software or data infrastructure, respectively.
- Both tool types are architected to promptly address issues that, if left unchecked, can escalate over time. Their primary focus is real-time issue detection, enabling timely resolution to eliminate business implications.
Differences
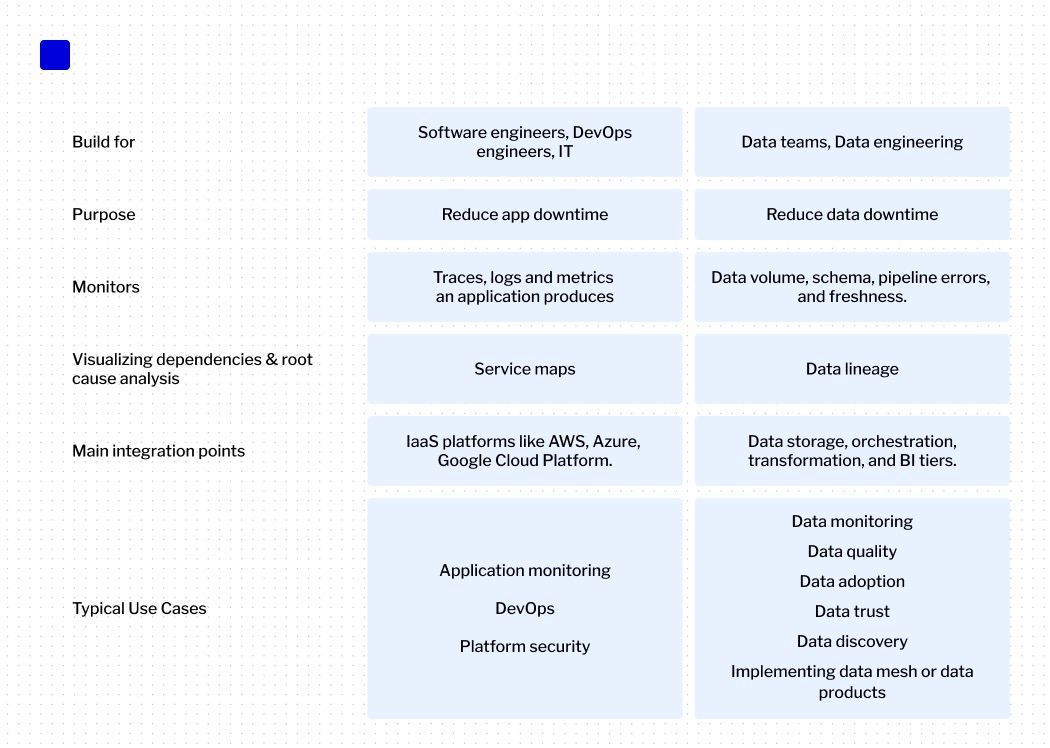
- Their core objectives differ: Software tools target application uptime and performance, whereas data observability aims to bolster data trust and reliability.
- They monitor distinct elements: Observability platforms like Datadog oversee software system logs, metrics, and traces. On the other hand, data observability monitors the health of the data environment, data pipelines, models, BI solutions, and integrations, provides data lineage, as well as measures the health of data tables through monitoring metrics like volume, schema, distribution, and freshness.
- Visualization of dependencies also differs. Where software tools offer service maps to engineers, data observability is a crucial part is a column-level data lineage, illustrating upstream and downstream data flows.
- Their integration touchpoints are distinct. Software solutions might integrate with IaaS platforms, while data observability often focuses on data storage, orchestration, and business intelligence systems, ETLs, and data ingestion solutions, in other words, the data engineering ecosystem.
Why Log-Centric Data Observability is an Ideal Scenario
Most data observability solutions employ SQL queries for data insight, which actually makes this solution a data quality product rather than a data observability solution (I probably will need to have a separate blog post about it later). Log-focused has been proved to be a strategy is the gold standard is software observability and will prevail in the long run among data observability, too. The advantages of this approach include:
- Enhanced security: Direct data isn’t accessed, safeguarding sensitive data and adhering to stringent data protection norms.
- Cost efficiency: The absence of SQL queries equates to lower cloud expenses.
- Ability to alert about any issues in real time, as any SQL queries are scheduled jobs and run periodically to check the state of data.
Wrapping Up Log-focused data observability presents an array of benefits, encompassing heightened data quality and reliability without security compromises or escalated cloud expenses via SQL queries. With Masthead, receive real-time data quality notifications, ensuring flawless data for end-users and accurate decision-making.





